
March 3, 2015
Weekly Update
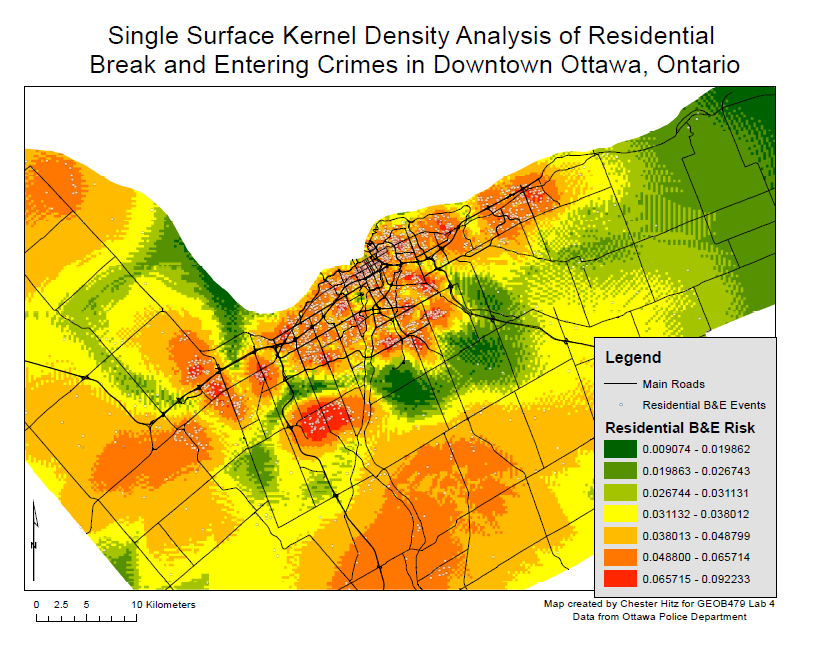
This week we discussed the applications of GIS to health (or medical) geographies. Several topics were discussed, including spatial epidemiology, environmental hazards, modeling health services, and identifying health inequalities. For this blog entry, I am going to focus on mapping environmental hazards.
Environmental hazards differ across the landscape. Certain areas are more prone to pollutants and other detrimental factors than others, and GIS can help to analyze and visualize these areas as to better understand them. Generally, environmental hazards can be understood in three dimensions:
- Hazard surveillance: this involves the mapping of the hazards themselves. This might include mapping polluting factories, toxic dumpsites, nuclear reactors, or former facilities that are still causing pollution.
- Exposure surveillance: this involves mapping the exposure to detrimental pollution caused by the hazards.
- Outcome surveillance: this is more closely aligned with other aspects of medical geography and involves the mapping of health outcomes produced by exposure to the hazard.
Often, these dimensions work in interaction with one and other when attempting to understand environmental hazards. For example, overlaying a map of hazards on a map of health outcomes caused by those hazards and then analyzing them (using geographically weighted regression, Morans I, etc) could produce powerful insight into the hazards and their subsequent effects.
GIS has been used prolifically to map health hazards since it has come into maturity. Examples include mapping asthma as a result of air pollution in the Bronx (NYC), mapping air toxins from a yeast factory in Oakland, or mapping the Bhopal disaster in India. However, I can't help thinking of how useful GIS would have been in several famous historical instances of environmental pollution that had human health impacts.
One such case is Love Canal, an ironically named neighborhood in Niagara Falls that was built on top of a terrible toxic waste dump. It was an interesting case because rather than a case where toxic waste entered an inhabited area, the Love Canal case was described as a case where residences "overflowed into the wastes instead of the other way around." To summarize the rather unbelievable story, a school district bought and then developed two elementary schools on an abandoned toxic dump despite warnings from the chemical company and many scientists. Several homes were constructed near the site as well. It did not take long for terrible health effects to emerge and soon Love Canal became a national scandal and well-known planning disaster.
.jpeg?timestamp=1426463373277)
A scene at Love Canal.
It certainly would have been interesting to see how the Love Canal scandal would have changed had GIS technology been around at the time. Though negligence, not lack of data, seems to be the chief culprit in the Love Canal disaster, it is an interesting thought experiment to wonder how GIS might have mitigated the issues at Love Canal, or at least have brought further justice for the victims. By mapping the toxic dump site and the health cases around it, perhaps a more solid case could have been built for the victims or something could be learned about the spread of toxins through groundwater. Nonetheless, the emergence of GIS has been a great benefit for understanding environmental hazards.